

Downtime is costing businesses a staggering $400 billion every year. That’s the finding of a landmark report from Splunk and Oxford Economics. It’s scary reading, but useful evidence for Alt Cloud providers when pitching their services.
The recent AWS outage showed that hyperscalers are not immune to downtime, and the report measures the financial cost of such service disruptions. It states that among the Global 2000, each enterprise loses an average of $200 million annually to unplanned downtime — equivalent to about 9% of its profits. Ouch.
The findings, based on surveys of 2,000 executives worldwide, show just how high the stakes have become for enterprise IT and the Cloud ecosystem that supports it. They also create a compelling case for providers of alternative Cloud computing strategies and solutions.
Downtime’s Domino Effect
The report found that the financial impact of downtime goes far beyond a few lost hours of productivity.
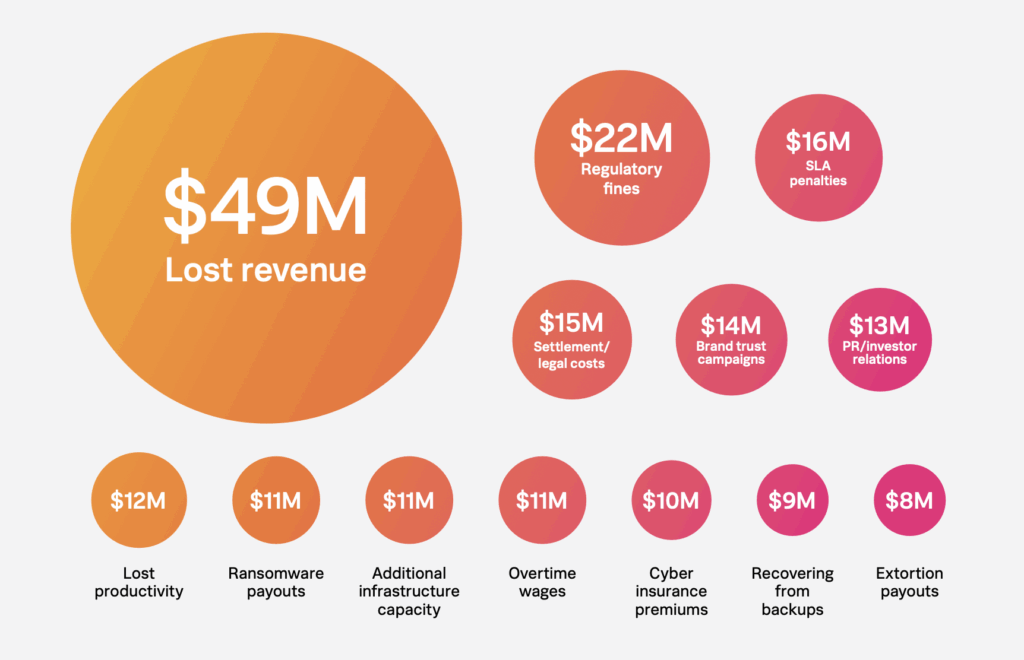
- Lost revenue: Enterprises lose an average of $49 million each year to service outages.
- Regulatory fines and SLA penalties: Together, they add another $38 million to the bill.
- Brand damage: CMOs report spending $14 million on trust-rebuilding campaigns and $13 million on public and investor relations after incidents.
- Stock performance: A single outage can knock 2.5% off a company’s market value, taking roughly 79 days to recover.
And that’s just the measurable damage. The hidden costs run deeper: lost customer trust, delayed product launches, and frozen innovation pipelines. Nearly three-quarters of technology executives surveyed said downtime slowed time-to-market for new offerings.
Why Downtime Keeps Happening
Despite huge investments in Cloud infrastructure and cybersecurity, downtime is rising and its causes are shifting. As it turns out, there seems to be a loose connection between the chair and the keyboard.
Splunk’s research found that 56% of downtime incidents stem from cybersecurity failures, while 44% arise from infrastructure or software issues. Across both categories, human error remains the leading culprit.
Even the most sophisticated hyperscalers struggle to contain it.
- On October 20, 2025, an AWS US-EAST-1 outage caused widespread disruption when customers were unable to connect to DynamoDB due to a latent defect within the service’s automated DNS management system
- Later in October, Microsoft Azure experienced outages, also linked to DNS issues.
- Google Cloud faced its own network failure in June, impacting its own platforms as well as external services such as Spotify and Discord.
When the world’s largest Cloud providers go down, the ripple effects touch every tier of business. Enterprises depending on a single hyperscaler can find themselves paralyzed — not because their own systems failed, but because their provider has gone dark.
The True Business Case for Cloud Computing Resilience
Gary Steele, Cisco’s President for Go-to-Market and GM of Splunk, frames the issue bluntly:
“The financial impact of downtime should have every board and every technology leader making digital resilience a priority.”
Resilience isn’t just about recovering quickly—it’s about architecting for continuity. Splunk’s data highlights a small group of “resilience leaders” who recover 23–28% faster from outages and reduce annual downtime losses by tens of millions of dollars. These leaders invest in observability, cross-team collaboration, and—importantly for this community—diversified infrastructure.
That’s where the conversation turns from “how do we prevent downtime?” to “how do we limit its blast radius?”
The Hidden Risk of Cloud Concentration
For years, enterprises were told that consolidation moving everything to a single hyperscaler was the path to efficiency. But centralization is now becoming a liability.
When workloads, data, and applications are concentrated in one provider’s stack, any regional or systemic failure can cascade through dependent systems. The same economies of scale that make hyperscalers so powerful also make them single points of failure.
The recent outages make that painfully clear: one misconfiguration can strand thousands of businesses worldwide.
For CFOs and boards now scrutinizing the total cost of downtime, this is forcing a rethink. Diversifying Cloud vendors is no longer an operational preference—it’s becoming a risk-management necessity.
Enter the Alternative Cloud Adoption
A new generation of alternative and regional Cloud providers is positioning itself as the antidote to fragility. By design, they offer a blend of flexibility, geographic diversity, and personal accountability that’s hard for the hyperscalers to match.
Here’s why enterprises are taking notice:
- Geographic and regulatory resilience
Regional Cloud providers can help organizations meet compliance demands like Europe’s Digital Operational Resilience Act (DORA) while reducing exposure to single-region outages. - Transparent operations
Many smaller providers differentiate through clear SLAs, direct communication, and service visibility traits that hyperscalers often obscure behind global support portals. - Industry specialisation
Alternative Clouds increasingly focus on specific verticals—finance, healthcare, manufacturing—building domain-tuned resilience capabilities and observability frameworks. - Multi-Cloud enablement
Working with multiple providers doesn’t have to be complex. The best alternative CSPs now design services that integrate seamlessly with AWS, Azure, and Google Cloud, giving enterprises the freedom to shift workloads dynamically when issues arise.
The Economics of Choice
Splunk’s study also revealed how resilience leaders spend smarter, not necessarily more. They invest in:
- Cybersecurity and observability tools that deliver rapid insight across hybrid environments.
- Backup capacity and cyber-insurance—with leaders spending up to $12 million more than others to safeguard business continuity.
- AI-driven analytics, where 65% already use generative AI tools to identify and remediate downtime causes.
These investments are amplified by architectural diversity. A multi-Cloud or hybrid-Cloud strategy distributes both workloads and risk—often improving uptime without inflating cost.
Building the Case for Change
For enterprise IT leaders, the takeaway is clear: resilience has become a financial metric. Every hour of downtime carries a price, and the board wants to see that number trending down.
To get there:
- Quantify downtime’s true cost: Track lost revenue, SLA penalties, and productivity drops. Make resilience ROI tangible.
- Adopt a multi-Cloud strategy: Use alternative and regional Clouds to decentralize workloads.
- Strengthen observability: Correlate data across all providers for a single source of truth.
- Create a resilience playbook: Define ownership, escalation, and recovery procedures before incidents occur.
- Plan for AI and automation: Use predictive analytics to catch anomalies early—but enforce governance to avoid new risks.
CloudFest: Where Resilience Meets Opportunity
As enterprises digest what $400 billion in annual downtime really means, CloudFest will be the place where the conversation shifts from problem to solution.
At CloudFest 2026, you’ll find:
- Resilience case studies from enterprises and providers who are turning downtime insights into uptime advantage.
- Alternative Cloud pioneers showcasing how distributed architectures deliver reliability, compliance, and customer trust.
- Hands-on workshops exploring observability, incident response, and multi-Cloud orchestration.
Because the truth is simple: the cost of downtime can’t be eliminated—but it can be contained. And the smartest way to do that is through choice, diversity, and collaboration across the entire Cloud ecosystem.
Contribute to this conversation—and help build a more resilient digital future—at CloudFest 2026.


